阅读笔记:Worker Selection Towards Data Completion for Online Sparse Crowdsensing
一、基本信息
- 阅读人和日期:XW Guo,2022.3.10
- 引用格式:W Liu, E Wang, et al. “Worker selection towards data completion for online sparse crowdsensing”, IEEE INFOCOM 2022 - IEEE Conference on Computer Communications, 2022.
- 单位:Jilin University and Temple University
- 原文链接: https://cis.temple.edu/~jiewu/research/publications/Publication_files/infocom%202022-online.pdf
- 概述:本文提出了一个在线稀疏群智感知的框架,称为 OS-MCS,它由三个部分组成:矩阵补全、重要性估计和工人选择。首先,从动态传入的数据开始,提出了一种具有时空约束的在线矩阵补全算法。其次,提出了一个可以持续更新的强化学习模型来估计时空区域的重要性。最后,利用先知秘书问题来选择合适的工人以在线方式感知重要子区域从而提高数据补全质量。
二、动机及主要贡献
动机:
现有的稀疏群智感知工作大多属于离线场景,首先从一个已知的池中招募工人来执行一些感知任务,然后在接收到所有数据后推断出其余的任务。现有的工作忽略了更符合实际的在线场景,在在线场景中,用户将实时参与并且动态提交感知数据。
主要贡献:
- 本文研究了在线场景下的稀疏群智感知。本文选择工人执行部分感知任务,通过处理实时参与的工人和他们提供的动态数据,以更实用的在线方式推断其余任务。
- 本文提出了一个有效的在线稀疏群智感知框架,称为 OS-MCS。首先,提出了一种时空约束下的在线矩阵补全算法。在此基础上,利用持续更新的强化学习进行子区域重要性估计。最后,提出了一种基于先知秘书的在线工人选择策略,旨在选择工人以在线方式主动感知对数据补全更有效的重要子区域。
- 本文使用真实数据集对五个典型的感知任务进行广泛评估,验证了所提出的在线稀疏群智感知方法的有效性。
三、问题描述和方法论
1. 问题描述
给定一组具有$m$个子区域和$n$个周期的任务,预算为$B$,持续时间为$T$,本文的问题是选择一组连续参与的工人$\mu$,目的是在整个在线处理过程中最小化总完成误差:
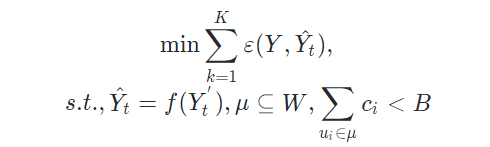
2. 在线矩阵补全
给定不完整的感知矩阵$Y^′$,我们可以利用低秩属性来补全完整的矩阵$\hat{Y}$:
$$
\min rank(\hat{Y}), s.t., \hat{Y}\otimes{M}=Y^{‘}
$$
将低秩矩阵$\hat{Y}$分解为两个高矩阵$U$和$V$的相乘,在某些条件下,最小化上述公式等价于最小化$U$和$V$的F范数。引入时空约束后,变为求解: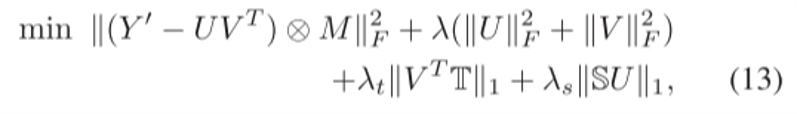
在线更新:使用修改后的交替最小二乘 (ALS),它根据等式(13)迭代地更新时空矩阵$U$和$V$,进而得到完整的矩阵$\hat{Y}$。
3. 子区域重要性估计
使用强化学习将时空区域与补全精度直接联系起来,以估计其对矩阵补全的重要性。
状态$S$:掩码矩阵,即对区域的覆盖情况。
动作$A$:当前感知区域,表示为$A = {a_1,a_2,…,a_m}$。
奖励$R$:直接使用完成误差来制定奖励: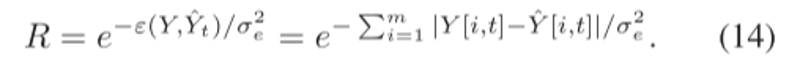
保持DQN模型最新:
具体来说,对于每个即将到来的数据,我们从时间和空间两个方面更新训练数据。使用图像处理中的Zoom方法,保持数据的分布来更新训练数据: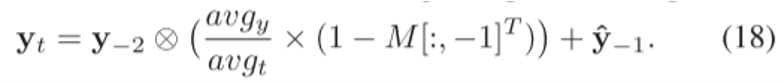
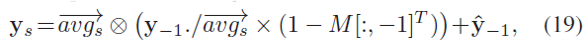
当前周期的新数据更新为:
$$
y_{-1}=\lambda_{t}y_t+\lambda_{s}y_s
$$
4. 工人选择
在在线场景中,工人实时参与,我们应该立即根据其覆盖的区域的重要性来决定是否选择他,而不知道未来的信息。
通过选定的集合$\mu$,根据其在已覆盖区域$s_\mu$下的感知区域$a_u$来估计工人$u$的效用:
$$
f(\mu,u)=(T-t_u)\cdot{Q(s_\mu,a_u)}
$$
式中,$Q(s_\mu,a_u)$是强化学习的Q值,表示在状态$s_\mu$下采取动作$a_u$的累积奖励。
•基于k-段秘书的工人选择
(1) 首先,使用历史记录来粗略估计预算$B$下被选中的工人数量$k$。
(2) 然后,将$w$个工人分成$k$段,并尝试从每段中选出最好的一个,即观察前$1/e\cdot{w/k}$个工人,并选择第一个比前面观察到的具有更大效用的工人。
(3) 每次选择一个工人后都会重新估计$k$,并重复(1)和(2) 。这种调整用于纠正不准确的$k$。
•改进为先知秘书问题求解
在传统的秘书问题中,工人们是按照随机的顺序来的,观察和抛弃前百分$1/e$的工人,以了解他们的效用分布。这种观察是必要的,但仍然有点浪费。
在实践中,通常有一些历史记录可以用来学习工人的效用分布,而不是丢弃工人。本文进一步引入了先知问题,避免丢弃工人导致错过最优者的情况。
四、实验部分
1)数据集
•PM2.5
•Temperature, Humidity
•Traffic, Parking
2)基线方法
(1) 对于矩阵补全:将本文的在线矩阵补全算法(ON)与其离线版本 (STMC)、经典矩阵补全(MC)和深度矩阵分解(DMF) 进行比较。
(2) 对于重要性估计:将本文的持续更新模型(UTD)与经典的Deep-Q Network (DQN)和委员会查询(QBC)进行比较。
(3) 对于工人选择:将本文的基于先知-秘书的策略 (PRO) 与基于秘书的策略(DYN)、接近最优的离线策略(OFF)、在线激励机制(OMZ)和基本随机方法(RAN)比较。
3)实验结果
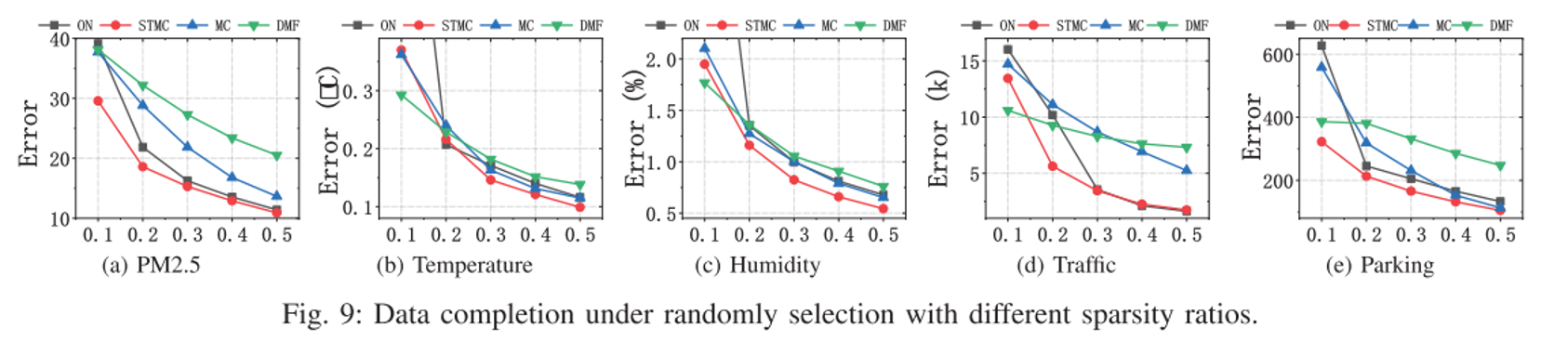
矩阵补全实验
随机选择时空区域,并将稀疏率从0.1变化至0.5。
可以看到,在大多数情况下,本文的ON接近其离线版本并优于其他算法。
重要性估计实验
使用模型来选择和感知一些时空区域并评估它们的完成(通过ON)误差。
如图所示,本文的UTD总是优于其他比较方法,这表明最新的训练是有效和必要的。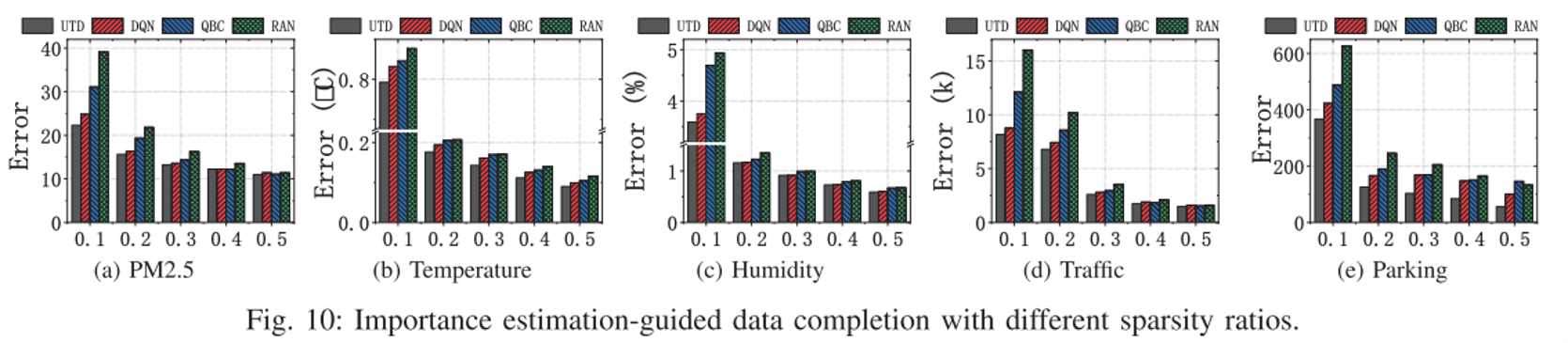
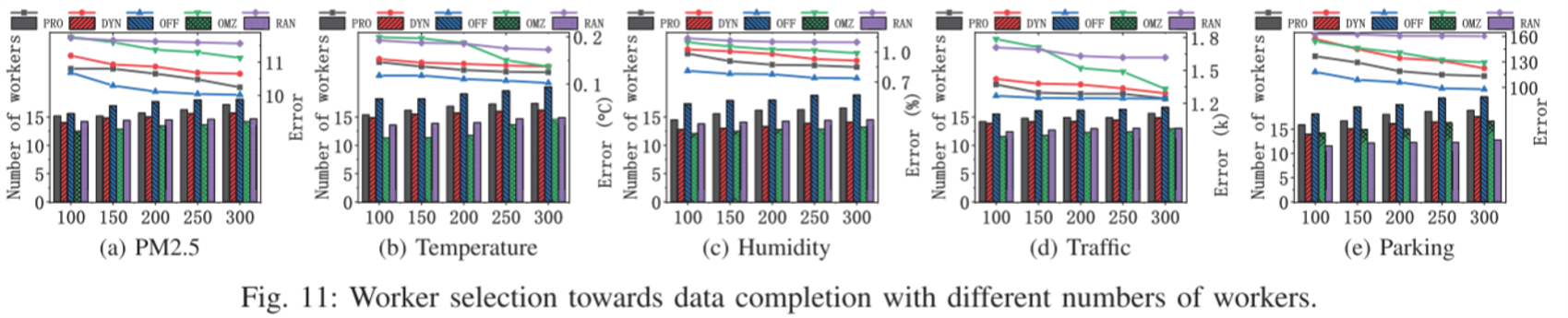
工人选择实验
将工人的平均成本设置为20,预算约束B=300。为了有效地评估本文的PRO对数据完成的影响,将工人的总数从100变化至300。
可以看到,除了接近最优的OFF之外,本文的PRO优于其他所有方法。